Representing Network Data for Machine Learning Models
Data representation plays a critical role in the performance of novelty detection methods from machine learning (ML). Our research agenda is exploring how different representations of network traffic can facilitate new breakthroughs in statistical inference based on network traffic.
We are currently exploring several avenues and have cases released software packages with the associated ongoing research:
- nPrint represents packets as standard bitmaps for use in a wide range of classification problems (device identification, application identification, etc.)
- NetML produces standard representations of packet captures as multi-dimensional timeseries data with a focus on unsupervised learning problems (e.g., outlier detection).
nPrint
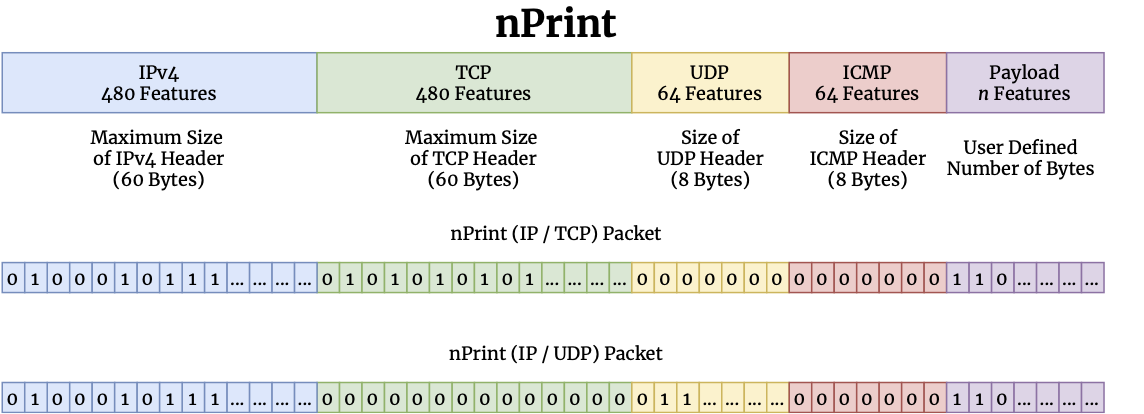
nPrint is a standard data representation for network traffic meant to be directly usable with machine learning algorithms, replacing feature engineering for a wide array of traffic analysis problems. Conventional detection and classification ("fingerprinting") problems involving network traffic commonly rely on either rule-based expert systems or machine learning models that are trained with manually engineered features derived from network traffic. Automated approaches in this area are typically tailored for specific problems. This paper presents nPrint, a standard, packet-based representation of network traffic that can be used as an input to train a variety of machine learning models without extensive feature engineering. We demonstrate that nPrint offers a suitable traffic representation for machine learning algorithms across three common network traffic classification problems: device fingerprinting, operating system fingerprinting, and application identification.
For more advanced usage and details see the project page.
NetML
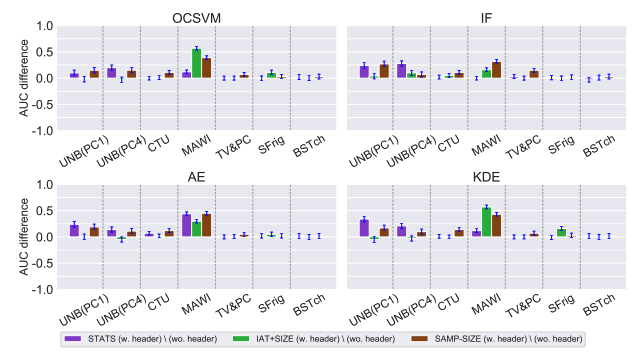
Data representation plays a critical role in the performance of novelty detection methods from machine learning. Network traffic has conventionally posed many challenges to conventional anomaly detection, due to the inherent diversity of network traffic. Even within a single network, the most fundamental characteristics can change; this variability is fundamental to network traffic but especially true in the Internet of Things (IoT), where the network hosts a wide array of devices, each of which behaves differently, exhibiting high variance in both operational modalities and network activity patterns.
Although there are established ways to study the effects of data representation in supervised learning, the problem is particularly challenging and understudied in the unsupervised learning context, where there is no standard way to evaluate the effect of selected features and representations at training time. This work explores different data representations for novelty detection in the Internet of Things, studying the effect of different representations of network traffic flows on the performance of a wide range of machine learning algorithms for novelty detection for problems arising in IoT, including malware detection, the detection of rogue devices, and the detection of cyberphysical anomalies.
Selected Publications
-
nPrint: A Standard Data Representation for Network Traffic Analysis.
Holland, Jordan, Paul Schmitt, Nick Feamster, and Prateek Mittal.
arXiv preprint arXiv:2008.02695 (2020). -
A Comparative Study of Network Traffic Representations for Novelty Detection.
Kun Yang, Samory Kpotufe, and Nick Feamster.
arXiv preprint arXiv:2006.16993 (2020).

